データ構造化ソリューション「DX-laei」
社内に蓄積された文書や書類などの非定型なデータを構造的なデータに整理し、AIの知識に変換します。
そのデータを基にAIが学習することで、高い精度を保つことができます。
企業が本格的に生成AIを活用するためには
社内には、PDFやドキュメントなど、さまざまな形式の文書が存在します。
その多くは「非構造的データ」と呼ばれ、書式や構造が定まっていないため、AIにとっては扱いづらい状態です。
近年のAIは、ある程度の自然言語を理解できるようになりましたが、非構造的なデータをそのまま処理するには不十分です。
これらの文書を活用するには、まず非構造的データを整理し、AIが理解しやすい形に変換(構造化)する必要があります。
データ構造化ソリューション
「DX-laei」
- 日本語特化型のトークナイザー
- 人手による知識構築
- 日本語の大規模言語DB(辞書)
- 高いカスタマイズ性
- 独自の自然言語処理技術
- 細やかな改善・チューニング
構造化により、検索・情報取得の精度を向上
AIの検索を強化する「RAG(Retrieval-Augmented Generation)」を用いて、情報を構造化。
検索データベースに情報を格納します。
データ構造化ソリューションによる検索精度の向上施策例
図表やグラフ、画像のテキスト化
- テキスト抽出
- Markdown記法化
- Mermaid記法化
高度なテキストアノテーション
- メタデータ付与(品詞・分野等)
- 文脈理解(意味・意図・感情)
- 固有表現・専門用語の理解
ドキュメントと質問文(クエリ)の
マッチング精度向上
- 文脈理解によるチャンキング
- 質問文の意図理解
- 同義語・類義語拡張
例1:画像からのテキスト抽出・Markdown化

データ引用元: ILU社内資料
![]()
1. 対話エンジン:
- 対話意図13万種類
- 標準応答文34万文
2. 文生成エンジン(詳細なデータ記載なし)
3. 感性分類エンジン:
- 感性81分類(420億パターン)
- 細分化分類14種類
- ヘルスケア分類41分類
4. 話題分類エンジン:
- 話題980分類(22億パターン)
5. 地域分類エンジン:
- 地域256分類
6. 重要表現抽出エンジン:
- キーワード種別36種類
7. 不適切表現抽出エンジン:
- 不適切表現3種類(3,700万パターン)
8. 格構造解析エンジン(詳細なデータ記載なし)
9. 形態素解析エンジン:
- 基本単語1,300万語
- 企業名・組織名41万語
- 商品名・著作物名30万語
- ヘルスケア単語30万語
- 品詞906種類
- 単語概念7.6万種類
例2:グラフからのテキスト抽出・Markdown化
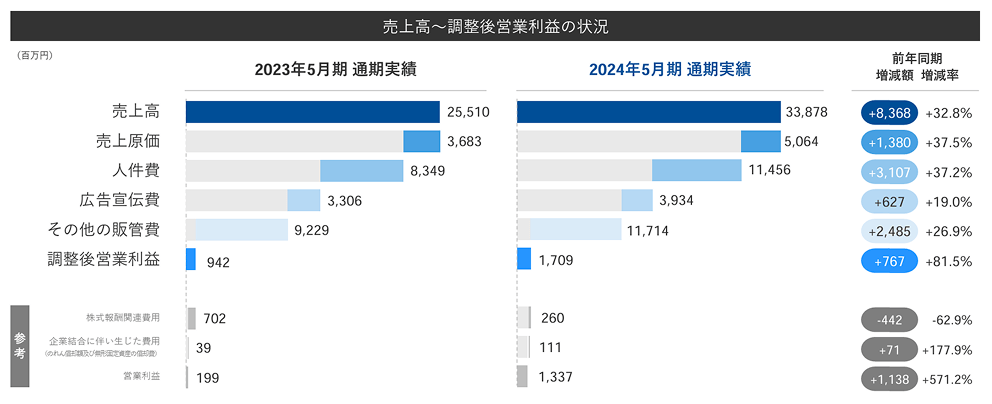
データ引用元: Sansan株式会社 2024年5月期 通期決算説明資料
![]()
表のタイトル: 売上高・調整後営業利益の状況
各項目の2023年5月期通期実績、2024年5月期通期実績、前年同期増減額、増減率は以下の通りです:
1. 売上高
2023年5月期: 25,510百万円
2024年5月期: 33,878百万円
増減額: +8,368百万円 (+32.8%)
2. 売上原価
2023年5月期: 3,683百万円
2024年5月期: 5,064百万円
増減額: +1,380百万円 (+37.5%)
3. 人件費
2023年5月期: 8,349百万円
2024年5月期: 11,456百万円
増減額: +3,107百万円 (+37.2%)
4. 広告宣伝費
2023年5月期: 3,306百万円
2024年5月期: 3,934百万円
増減額: +627百万円 (+19.0%)
例3:フローチャートからのテキスト抽出・Mermaid化
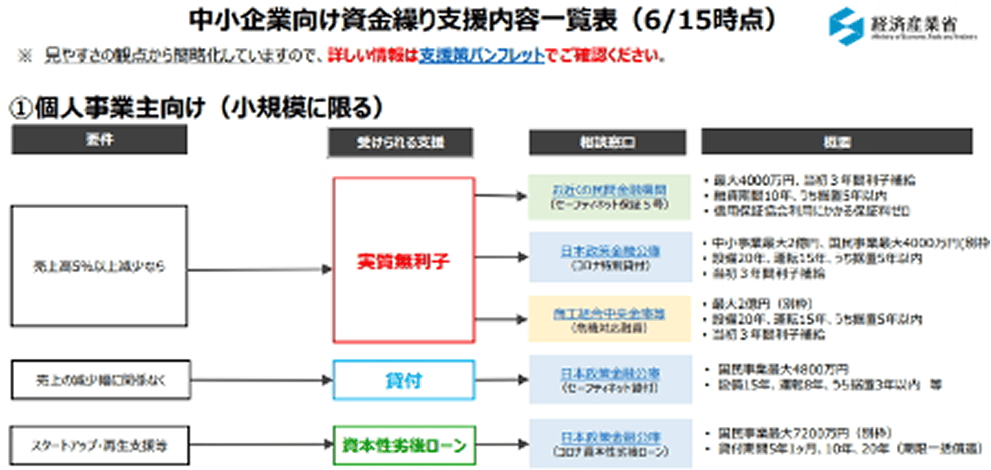
![]()
**① 個人事業主向け (小規模に限る)**
A[要件] –> B{売上高5%以上減少なら}
A –> C{売上の減少幅に関係なく}
A –> D{スタートアップ・再生支援等}
B –> E[実質無利子]
C –> F[貸付]
D –> G[資本性劣後ローン]
E –> H(お近くの民間金融機関
(セーフティネット保証5号))
E –> I(日本政策金融公庫
(コロナ特別貸付))
E –> J(商工組合中央金庫等
(危機対応融資))
F –> K(日本政策金融公庫
(セーフティネット貸付))
G –> L(日本政策金融公庫
(コロナ資本性劣後ローン))
H –> M((概要))
I –> N((概要))
J –> O((概要))
K –> P((概要))
L –> Q((概要))
高度なテキストアノテーションによるマッチング精度向上
| 前処理例 | 内容 |
|---|---|
| メタデータ付与(分野・地域) | テキストの構造や内容を解析し、分野や地域といった属性情報を付加。 |
| 文脈理解(意味・感情) | 文脈(コンテキスト)を考慮してテキストに表れていない情報を解析・付加。 |
| 固有表現・専門用語の理解 | テキスト中の固有表現や専門用語を識別。その意味や関係性などを理解。社内用語や略語なども含む。 |
| 文脈理解によるチャンキング | 品詞(名詞句や動詞句)や文脈の意味ごとにテキストを一定の単位で分割。 |
| 質問文の意図理解 | 質問の形式や内容から質問者の本当の意図(背景や期待)を解析・付加。 |
| 同義語・類義語拡張 | テキストにある単語や表現を、文脈を理解した上で適切な同義語・類義語で言葉を拡張。 |
国内最大規模の言語データベース
国内最大規模の言語データベースを保有しているからこそ、高度なテキスト選別が可能になります。
-

対話意図
19万5000種類 -

ヘルスケア分類
41分類 30万語 -

キーワード種別
36種類 -

企業名・組織名
52万語 -

商品名・著作物名
45万語 -

話題
980分類
23億パターン -

不適切表現
3種類
5000万パターン -

感性
81分類
663億パターン -
標準応答文
47万文 -

地域
256分類 -
基本収録単語
1,300万語 -
単語概念
8.8万語 -

細分化分類
18種類 -
品詞
920種類
カスタマイズ開発により、
個社に最適化された基盤を構築
-
企業が保有するデータ
図表、PDF、動画、音声のドキュメント類

-
ソリューション
社内特有の固有表現、略称、言い回し等の辞書を構築

-
AIが扱える知識
企業の蓄積された社内情報をAIが「知識化」




構造化により構築された、AIの「知識」の良いところ
-

比較的低コストで成果が出る
RAGの精度改善には多くのテクニックが生まれていますが、検索データベース部分の「前処理」は確実に成果が出ます。かつ、自然言語処理技術を用いることで、低コストで取り組むことが可能です。
-

既存業務の変更は不要
既存業務にて作成・運用されている文書や書類を変換する仕組みであるため、既存業務の変更が不要で、スイッチコストは発生しません。
-

陳腐化しない
生成AIは日進月歩で新しいモデルが誕生しますが、知識化された社内データはそのまま利用が可能。継続的に蓄積していくことで、AI時代の競争優位性に確実につながります。